![animato_logo]()
Hi there! It’s probably time to make this somewhat official:
Here is a selection of the most pressing “big ticket” animation related developments currently on my todo list. Do note that this is not an exhaustive list (for which there are many other items), but it does contain all the main things that I’m most aware of.

(This is cross-posted from my original post: http://aligorith.blogspot.co.nz/2015/03/animation-system-roadmap.html)
High Priority
NLA
* Local Strip Curves – Keyframing strip properties (e.g. time and influence) currently doesn’t update correctly. [2.75]
Quite frankly, I’m surprised the current situation seems to work as well as it has, because the original intention here (and only real way to solve it properly) is to have dedicated FCurves which get evaluated before the rest of the animation is handled.
I’ve got a branch with this functionality working already – all that’s missing is code to display those FCurves somewhere so that they can be edited (and without being confused for FCurves in the active actions instead). That said, the core parts of this functionality are now solid and back under control in the way it was originally intended.
I originally wanted to get this polished and into master for 2.74 – definitely before Gooseberry start trying to animate, as I know that previous open movie projects did end up using the NLA strip times for stuff (i.e. dragon wings when flying), and the inclusion of this change will be somewhat backwards incompatible (i.e. the data structures are all still there – nothing changed on that front, but there were some bugs in the old version which means that even putting aside the fact you can’t insert keyframes where they’re actually needed, the animations wouldn’t actually get evaluated correctly!).
On a related note – the bug report regarding the renaming NLA strips not updating the RNA Paths: that is a “won’t fix”, as that way of keyframing these properties (that is used in master) was never the correct solution. This fix will just simply blow it all away, so no point piling another hack-fix on top of it all.
* Reference/Rest Track and Animation Layers Support [2.76]
This one touches on two big issues. Firstly, there’s the bug where, if not all keyframed properties are affected by every strip (or at least set to some sane value by a “reference” strip), you will get incorrect poses when using renderfarms or jumping around the timeline in a non-linear way.
On another front, the keyframing on top of existing layers (i.e. “Animation Layers”) support doesn’t work well yet, because keyframing records the combined value of the stack + the delta-changes applied by the active action that you’re keying into. For this to work correctly, the contributions of the NLA stack must be able to be removed from the result, leaving only the delta changes, thus meaning that the new strip will be accumulated properly.
So, the current plan here is that an explicit “Reference Pose” track will get added to the bottom of NLA stacks. It will always be present, and should include every single property which gets animated in the NLA stack, along with what value(s) those properties should default to in the absence of any contributions from NLA strips.
Alongside this reference track, all the “NlaEvalChannels” will be permanently stored (during runtime only; they won’t get saved to the file) instead of being recreated from scratch each time. They will also get initialised from the Reference Track. Then, this allows the keyframing tools to quickly look up the NLA stack result when doing keyframing, thus avoiding the problems previously faced.
* A better way to retime a large number of strips [2.76/7]
It’s true that the current presentation of strips is not exactly the most compact of representations. To make it easier to retime a large number of strips (i.e. where you might want them to be staggered across a large number of objects, we may need to consider having something like a summary-track in the dopesheet. Failing that, we could just have an alternative display mode which compacts these down for this usecase.
Action Management [2.74, 2.75]
See the Action Management post. The priority of this ended up being bumped up, displacing the NLA fixes from 2.74 (i.e. Local Strip Keyframes) and 2.75 (i.e. Reference Track Support) back by 1-2 releases.
There are also a few related things which were not mentioned in that post (as they did not fit):
* Have some way of specifying which “level” the “Action Editor” mode works on.
Currently, it is strictly limited to the object-level animation of the active object. Nothing else. This may be a source of some of the confusion and myths out there… (Surely the fact that the icon for this mode uses the Object “cube” is a bit of a hint that something’s up here!)
* Utilities for switching between Dopesheet and NLA.
As mentioned in the Action Management post, there are some things which can be done to make the relationship between these closer, to make stashing and layering workflows nicer.
Also in question would be how to include the Graph Editor in there somehow too… (well, maybe not between the NLA, but at least with the Dopesheet)
* “Separate Curves” operator to split off FCurves into another action
The main point of this is to split off some unchanging bones from an action containing only moving parts. It also paves the way for other stuff like take an animation made for grouped objects back to working on individual objects.
Animation Editors
* Right-click menus in the Channels List for useful operations on those [2.75]
This should be a relatively simple and easy thing to do (especially if you know what to do). So, it should be easy to slot this in at some point.
* Properties Region for the Action Editor [2.76]
So, at some point recently, I realised that we probably need to give the Action Editor a dedicated properties region too to deal with things like groups and also the NLA/AnimData/libraries stuff. Creating the actual region is not really that difficult. Again it boils down to time to slot this in, and then figuring out what to put in there.
* Grease Pencil integration into normal Dopesheet [2.76]
As mentioned in the Grease Pencil roadmap, I’ve got some work in progress to include Grease Pencil sketch-frames in the normal dopesheet mode too. The problem is that this touches almost every action editor operator, which needs to be checked to make sure it doesn’t take the lazy road out by only catering for keyframes in an either/or situation. Scheduling this to minimise conflicts with other changes is the main issue here, as well as the simple fact that again, this is not “simple” work you can do when half-distracted by other stuff.
Bone Naming [2.77]
The current way that bones get named when they are created (i.e. by appending and incrementing the “.xyz” numbers after their names) is quite crappy, and ends up creating a lot of work if duplicating chains like fingers or limbs. That is because you now have to go through, removing these .xyz (or changing them back down to the .001 and .002 versions) before changing the action things which should change (i.e. Finger1.001.L should become Finger2.001.L instead of Finger1.004.L or Finger1.001.L.001).
Since different riggers have different conventions, and this functionality needs to work with the “auto-side” tool as well as just doing the right thing in general, my current idea here is to give each Armature Datablock a “Naming Pattern” settings block. This would allow riggers to specify how the different parts of each name behave.
For example, [Base Name][Chain Number %d][Segment Letter][Separator ‘.’][Side LetterUpper] would correspond to “Finger2a.L”. With this in place, the “duplicate” tool would know that if should increment the chain number/letter (if just a single chain, while perhaps preparing for flipping the entire side if it’s more of a tree), while leaving the segment alone. Or the “extrude” tool would know to increment the segment number/letter while leaving the chain number alone (and not creating any extra gunk on the end that needs to be cleaned up). The exact specifics though would need to be worked out to make this work well.
Drivers
* Build a dedicated “Safe Python Subset” expression engine for running standard driver expressions to avoid the AutoRun issues
I believe that the majority of driver expressions can be run without full Python interpreter support, and that the subset of Python needed to support the kinds of basic math equations that the majority of such driver expressions use is a very well defined/small set of things.
This set is small enough that we can in fact implement our own little engine for it, with the benefit that it could probably avoid most of the Python overheads as a result, while also being safe from the security risks of having a high-powered turing-complete interpreter powering it. Other benefits here are that this technique would not suffer from GIL issues (which will help in the new depsgraph; oddly, this hasn’t been a problem so far, but I’d be surprised if it doesn’t crop up its ugly head at the worst possible moment of production at some point).
In the case where it cannot in fact handle the expression, it can then just turf it over to the full Python interpreter instead. In such cases, the security limiting would still apply, as “there be dragons”. But, for the kinds of nice + simple driver expressions we expect/want people to use, this engine should be more than ample to cope.
So, what defines a “nice and simple” driver expression?
– The only functions which can be used are builtin math functions (and not any arbitrary user-defined ones in a script in the file; i.e. only things like sin, cos, abs, … would be allowed)
– The only variables/identifiers/input data it can use are the Driver Variables that are defined for that driver. Basically, what I’ve been insisting that people use when using drivers.
– The only “operators” allowed are the usual arithmetic operations: +, -, *, /, **, %
What makes a “bad” (or unsafe) driver expression?
– Anything that tries to access anything using any level of indirection. So, this rules out all the naughty “bpy.data[…]…” accesses and “bpy.context.blah” that people still try to use, despite now being blasted with warnings about it. This limitation is also in place for a good reason – these sorts of things are behind almost all the Python exploits I’ve seen discussed, and implementing such support would just complicate and bloat out little engine
– Anything that tries to do list/dictionary indexing, or uses lists/dictionaries. There aren’t many good reasons to be doing this (EDIT: perhaps randomly chosing an item from a set might count. In that case, maybe we should restrict these to being “single-level” indexing instead?).
– Anything that calls out to a user-defined function elsewhere. This is inherent risk here, in that that code could do literally anything
– Expressions which try to import any other modules, or load files, or crazy stuff like that. There is no excuse… Those should just be red-flagged whatever the backend involved, and/or nuked on the spot when we detect this.
* A modal “eyedropper” tool to set up common “garden variety” 1-1 drivers
With the introduction of the eyedropped tools to find datablocks and other stuff, a precedent has been set in our UI, and it should now be safe to include similar things for adding a driver between two properties. There are of course some complications which arise from the operator/UI code mechanics last time I tried this, but putting this in place should make it easier for most cases to be done.
* Support for non-numeric properties
Back when I initially set up the animation system, I couldn’t figure out what to do with things like strings and pointers to coerce them into a form that could work with animation curves. Even now, I’m not sure how this could be done. That said, while writing this, I had the though that perhaps we could just use the same technique used for Grease Pencil frames?
Constraints
* Rotation and Scale Handling
Instead of trying to infer the rotation and scale from the 4×4 matrices (and failing), we would instead pass down “reference rotation” and “reference scale” values alongside the 4×4 matrix during the evaluation process. Anytime anything needs to extract a rotation or scale from the matrix, it has to adjust that to match the reference transforms (i.e. for rotations, this does the whole “make compatible euler” stuff to get them up to the right cycle, while for scale, this just means setting the signs of the scale factors). If however the rotation/scale gets changed by the constraint, it must also update those to be whatever it is basing its stuff from.
These measures should be enough to combat the limitations currently faced with constraints. Will it result in really ugly code? Hell yeah! Will it break stuff? Quite possibly. Will it make it harder to implement any constraints going forth? Absolutely. But will it work for users? I hope so!
Rigging
It’s probably time that we got a “Rigging Dashboard” or similar…
Perhaps the hardest thing in trying to track down issues in the rigs being put out by guys like JP and cessen these days are that they are so complex (with multiple layers of helper bones + constraints + parenting + drivers scattered all over) to figure out where exactly to start, or which set of rigging components interact to create a particular result.
Simply saying “nodify everything” doesn’t work either. Yes, it’s all in one place now, but then you’ve got the problem of a giant honking graph that isn’t particularly nice to navigate (large graph navigation in and of itself is another interesting topic for another time and date).
Key things that we can get from having such a dashboard are:
1) Identifying cycles easier, and being able to fix them
2) Identifying dead/broken drivers/constraints
3) Isolating particular control chains to inspect them, with everything needed presented in one place (i.e. on a well designed “workbench” for this stuff)
4) Performance analysis tools to figure out which parts of your rig are slow, so that you can look into fixing that.
Medium Priority
NLA
* A better way of flattening the stack, with fewer keyframes created
In many cases, it is possible to flatten the NLA without baking out each frame. This only really applies when there are no overlaps, where the keyframes can simply be transposed “as is”. When they do interact though, there may be possibilities to combine these in a smarter way. In the worst case, we can just combine by baking.
* Return of special handling for Quaternions?
I’m currently pondering whether we’ll need to reinstate special handling for quaternion properties, to keep things sane when blending.
* Unit tests for the whole time-mapping math
I’ve been meaning to do this, but I haven’t been able to get the gtests framework to work with my build system yet… If there ever wee a model example of where these things come in handy, it is this!
Animation Editors
* Expose the Animation Channel Filtering API to Python
Every time I see the addons that someone has written for dealing with animation data, I’m admittedly a bit saddened that they do things like explicitly digging into the active object only, and probably only caring about certain properties in there. Let’s just say, “been there done that”… that was what was done in the old 2.42/3 code, before I cleaned it up around 2.43/2.44, as it was starting to become such a pain to maintain it all (i.e. each time a new toggle or datatype was added, ALL the tools needed to be recoded).
These days, all the animation editors do in fact use a nice C API for all things channels-related. Some of it pre-dates the RNA system, so it could be said that there are some overlaps. Then again, this one is specialised for writing animation tools and drawing animation editors, while RNA is generic data access – no comparison basically.
So, this will happen at some point, but it’s not really an urgent/blocking issue for anything AFAIK.
* To support the filtering API, we need a way of setting up or supplying some more general filtering settings that can be used everywhere where there aren’t any the dopesheet filtering options already
The main reason why all the animation editor operators refuse to work outside of those editors is that they require the dopesheet filtering options (i.e. those toggles on the header for each datablock, and other things) to control what they are able to see and affect. If we have some way of passing such data to operators which need it in other contexts (as a fallback), this opens the way up for stuff like being able to edit stuff in the timeline.
As you’ll hopefully be well aware, I’m extremely wary of any requests to add editing functionality to the timeline. On day one, it’ll just be “can we click to select keyframes, and then move them around”, and then before long, it’s “can we apply interpolation/extrapolation/handle types/etc. etc.” As a result, I do not consider it viable to specifically add any editing functionality there. If there is editing functionality for the timeline, it’ll have to be borrowed from elsewhere!
Action Editor/Graph Editor
* Add/Remove Time
Personally I don’t understand the appeal of this request (maybe it’s a Maya thing), but nonetheless, it’s been on my radar/list as something that can be done. The only question is this: is it expected that keyframes should be added to enact a hold when this happens, or is this simply expanding and contracting the space between keyframes.
* Make breakdown keyframes move relative to the main keyframes
In general, this is simple, up until the keyframes start moving over each other. At that point, it’s not clear how to get ourselves out of that pickle…
Small FCurve/Driver/etc. Tweaks
* Copy Driver Variables
* Operators to remove all FModifiers
Motion Capture Data
* A better tool for simplifying dense motion curves
I’ve been helping a fellow kiwi work on getting his curve simplifying algorithm into Blender. So far, its main weakness is that it is quite slow (it runs in exponential time, which sucks on longer timelines) but has guarantees of “optimal” behaviour. We also need to find some way to estimate the optimal parameters, so that users don’t have to spend a lot of time testing different combinations (why is not going to be very nice, given the non-interactive nature of this).
Feel free to try compiling this and give it a good test on a larger number of files and let us know how you go!
* Editing tools for FSamples
FSamples were designed explicitly for the problem of tackling motion capture data, and should be more suited to this than the heavier keyframes.
Keying Sets
* Better reporting of errors
The somewhat vague “Invalid context” error for Keying Sets comes about because there isn’t a nice way to pipe more diagnostic information in and out of the Keying Sets callbacks which can provide us with that information. It’s a relatively small change, but may be better with
Pose Libraries
* Internal code cleanups to split out the Pose Library API from the Pose Library operators
These used to be able to serve both purposes, but the 2.5 conversion meant that they were quickly converted over to opertator-only to save time. But, this is becoming a bottleneck for other stuff
* Provide Outliner support for Pose Library ops
There’s a patch in the tracker, but this went about this in the wrong way (i.e. by duplicating the code into the outliner). If we get that issue out of the way, this is relatively trivial
* Pose Blending
Perhaps the biggest upgrade that can be made is to retrofit a different way of applying the poses, to be one which can blend between the values in the action and the current values on the rig. Such functionality does somewhat exist already (for the Pose Sliding tools), but we would need to adapt/duplicate this to get the desired functionality. More investigation needed, but it will happen eventually.
* Store thumbnails for Poses + Use the popup gallery (i.e. used for brushes) to for selecting poses
I didn’t originally do this, as at the time I thought that these sorts of grids weren’t terribly effective (I’ve since come around on this, after reading more about this stuff) and that it would be much nicer if we could actually preview how the pose would apply in 3D to better evaluate how well it fits for the current pose (than if you only had a 2D image to work off). The original intent was also to have a fancy 3D gallery, where scrolling through the gallery would swing/slide the alternatively posed meshes in from the sides.
Knowing what I know now, I think it’s time we used such a grid as one of the way to interact with this tool. Probably the best way would be to make it possible to attach arbitrary image datablocks to Pose Markers (allowing for example the ability to write custom annotations – i.e. what phenoms a mouth space refers to), and to provide some operators for creating these thumbnails from the viewport (i.e. by drawing a region to use).
Fun/Useful but Technically Difficult
There are also a bunch of requests I’d like to indulge, and indeed I’ve wanted to work on them for years. However, these also come with a non-insignificant amount of baggage which means that they’re unlikely to show up soon.
Onionskinning of Meshes
Truth be told, I wanted to do this back in 2010, around the time I first got my hands on a copy of Richard William’s book. The problem though was and remains that of maintaining adequate viewport/update performance.
The most expensive part of the problem is that we need to have the depsgraph (working on local copies of data, and in a separate thread) stuff in place before we can consider implementing this. Even then, we’ll also need to include some point caching stuff (e.g. Alembic) to get sufficient performance to consider this seriously.
Editable Motion Paths
This one actually falls into the “even harder” basket, as it actually involves 3-different “hard” problems:
1) Improved depsgraph so that we can have selective updates of only the stuff that changes, and also notify all the relationships appropriately
2) Solving the IK problem (i.e. changed spline points -> changed joint positions -> local-space transform properties with everything applied so that it works when propagated through the constraints ok). I tried solving this particular problem 3 years ago, and ran into many different little quirky corner cases where it would randomly bug/spazz out, flipping and popping, or simply not going where it needs to go because the constraints exhibit non-linear behaviour and interpret the results differently. This particular problem is one which affects all the other fun techniques I’d like to use for posing stuff, so we may have to solve this once and for all with an official API for doing this. (And judging from the problems faced by the authors of various addons – including the current editable motion paths addon, and also the even greater difficulties faced by the author of the Animat on-mesh tools, it is very much a tricky beast to tame)
3) Solving the UI issues with providing widgets for doing this.
Next-Generation Posing Tools
Finally we get to this one. Truth be told, this is the project I’ve actually been itching to work on for the past 3 years, but have had to put off for various reasons (i.e. to work on critical infrastructure fixes and also for uni work). It is also somewhat dependent on being able to solve the IK problem here (which is a recurring source of grief if we don’t do it right).
If you dig around hard enough, you can probably guess what some of these are (from demos I’ve posted and also things I written in various places). The short description though is that, if this finally works in the way I intend, we’ll finally have an interface that lets us capture the effortless flow, elegance, and power of traditional animating greats like Glen Keane or Eric Goldberg – for having a computer interface that allows that kind of fluid interaction is one my greatest research interests.
Closing Words
Looking through this list, it looks like we’ve got enough here for at least another 2-3 years of fun times ![😀]()


 ) get a bit of testing. In those builds you’ll find:
) get a bit of testing. In those builds you’ll find:




























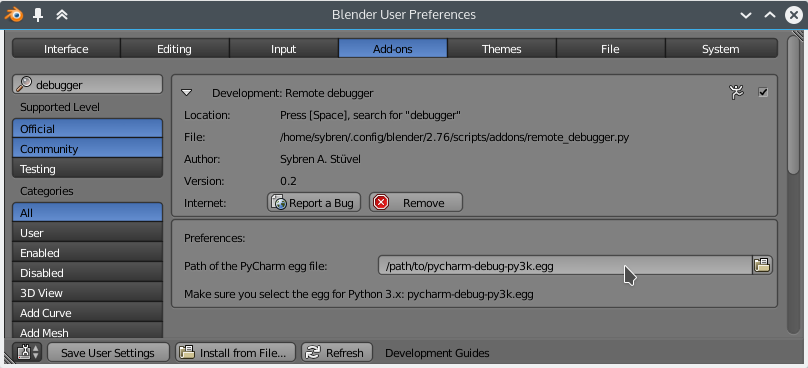

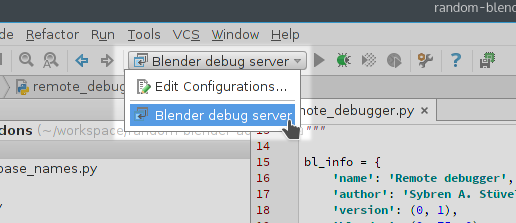
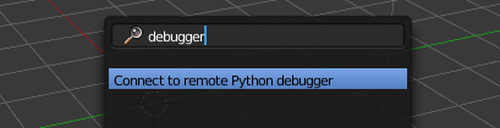


























 In this article we take a look at using logging inside Blender. When things take an unexpected turn, which they always do, it is great to know what is going on behind all the nice GUIs and user-friendly operators. Python’s standard library with a very flexible and extendable
In this article we take a look at using logging inside Blender. When things take an unexpected turn, which they always do, it is great to know what is going on behind all the nice GUIs and user-friendly operators. Python’s standard library with a very flexible and extendable 







